Introduction
Tutorials
Getting familiar with GeoData Manager
Changing how GeoData Manager looks
Scenarios for using GeoData Manager
Data types and nodes
Help with data types and nodes
Getting familiar with GeoData Manager
Changing how GeoData Manager looks
Scenarios for using GeoData Manager
Help with data types and nodes
This section is for users who want to understand and use GeoData Manager better.
A field is a single piece of data, for example a date, a time, a temperature measurement or a chemical concentration. You can display, print, import or export fields.
Every field has a value, a unit and a name; for example a temperature measurement field might have a value '28', a unit 'deg C' and a name 'Well temperature'. GeoData Manager stores data internally in SI units, but you can choose any units to enter and present data. If you changed the unit of the above temperature to 'deg F' then the field value displayed or printed would change accordingly.
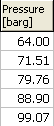
The field name and unit is usually displayed or printed near the field:
| Field name and unit to left of the value | or field name and unit above a column of fields |
|---|---|
 |
 |
GeoData Manager doesn't work with individual items of data (fields), instead it works with sets of data (sets of fields). Such a set is called a dataset. A dataset is usually:
Either data about a place. For example data describing a well, or data describing a geophysics measurement site.
Or data about a related group of measurements. For example pressures and temperatures from a downhole PT measurement or chemical concentrations from a chemistry sample.
A dataset can have different kinds of measurements, so for example a downhole PT dataset can have pressures and temperatures measured down the well, plus other data like the test start date and time. A dataset is one set of measurements, so for example if you do another downhole PT measurement then the results will be a different dataset.
GeoData Manager has different types of datasets, because datasets for different things store different kinds of data. For example, the data describing a well is different to the data from a downhole PT measurement. Thus, each dataset has a datatype, which tells GeoData Manager what data (fields) are in the dataset.
GeoData Manager has over 150 built-in datatypes. You can not make new datatypes, nor change the kinds of data that are stored in a dataset.
A dataset can have two kinds of data:
Data which only occurs once - this is called the header data. The header data includes general things like well name, test start date, test start time, the name of the contractor who did some work. The dataset's header data depends on the datatype.
Data which occurs many times - this is called the detail data. The dataset's detail data depends on the datatype. For example:
GeoData Manager's home window has available datatypes on the left and datasets for the selected datatype on the right. On the right, the header window shows the header data for the datasets and the detail tab below shows the detail data for the dataset selected in the header window.
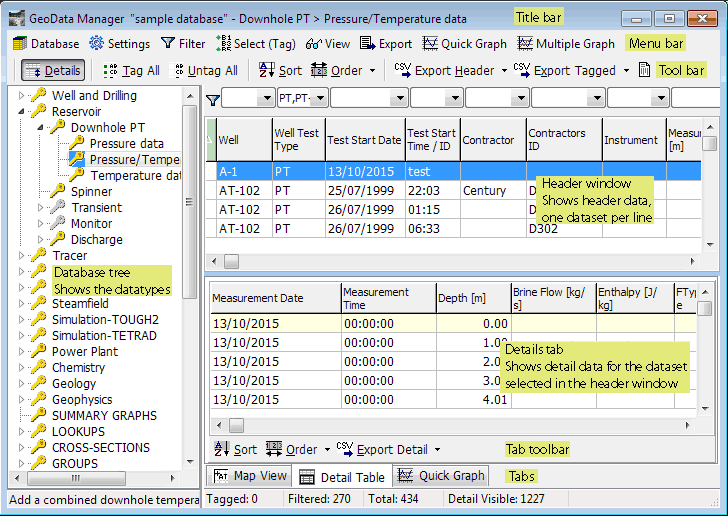
Note that in the database tree on the left the datatypes are the lines at the far right of the tree. For example, in the picture above, 'Pressure data', 'Pressure/Temperature data' and 'Temperature data' are datatypes. But 'Reservoir' and 'Downhole PT' are not datatypes: if you click one of these you will see datasets for the datatypes to the right. For example, if you click 'Downhole PT' you will see datasets with datatypes 'Pressure data', 'Pressure/Temperature data' and 'Temperature data'. This is for convenience when working with the datasets.
Each dataset has some special fields that GeoData Manager uses to distinguish one dataset from another. For example, for a downhole PT pressure data dataset, these fields are Well, Well Test Type, Test Start Date and Test Start Time/ID. Each of these fields is called an identifier and all the identifiers are called a key. You can think of the key as being the name of the dataset.
Each dataset's key must be different keys of other datasets of the same datatype. In other words, at least one identifier must be different to the identifiers of other datasets of the same datatype.
To ensure the key is unique, whan you create a new dataset you must enter all the identifiers first, then enter the rest of the data:
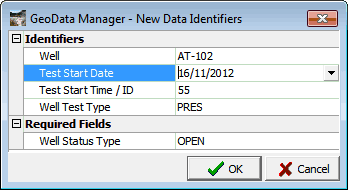
When you click OK, GeoData Manager checks that at least one identifier is different to the identifiers of existing datasets of that datatype.
To find the identifiers for a given datatype, go to create a new dataset of that datatype; the window has the identifiers (see above).
When you create a new dataset (see screenshot above) you might be required to enter more data, called the required fields. For example, when you enter a new downhole PT pressure data dataset you are asked to enter a well status type. GeoData Manager does not use the required fields as part of the key; the required fields are just fields that you have decided must be entered for datasets of that datatype.
You can change the required fields:
Tools > Set required fields for New: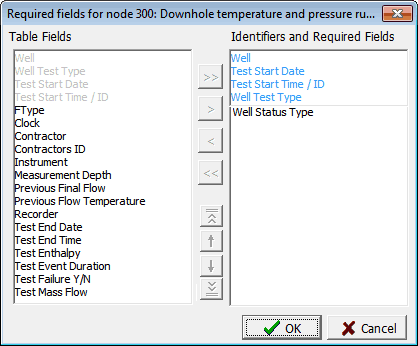
Table fields lists the available fields. The identifiers are grey because they must be in 'Indentifiers and required fields'
Identifiers and required fields
The identifiers are blue: you can not remove them.
The required fields are black, and you can add or remove these.
You can change the order of the identifiers and required fields. This changes their order when you enter data for a new dataset, or rename the dataset:
Rearrange the fields the same way as you changed column order see here.
For advanced users. A GeoData Manager database is a relational database. Both Access and SQL server databases are relational databases. For a relational database, data is stored as records in blocks of data called tables, which notionally have rows and columns: each row has data for a record, and each column is a field in a record. A dataset in GeoData Manager is usually stored in two tables:
The header data is stored in one row in a table, called the header table; the other rows have header data for other datasets of that datatype. GeoData Manager's home window's header window shows the header table for that dataset: one row for each dataset and one column for each header data field.
The detail data for a data set is stored one whole table, called the detail table, because it has fields that are repeated down the rows. GeoData Manager's home window's Detail Table tab shows the detail table of the data set selected in the header window: one row for each record and one column for each detail data field. Note: in some datatypes the detail data for a data set is stored more than one table.
For advanced users. This has information that tells GeoData Manager about the current data type.
To see the table, click View, then Show the P-Tree system table. To dismiss the table, click X at the top, right:
| Name | Purpose |
|---|---|
| Parent, Node | Where the datatype is in the database tree |
| HeaderShow | The name of the header table |
| HeaderKeyCount | The number of identifiers |
| DetailShow | The name of the detail table |
| DetailKeyCount | The number of identifiers plus the number of required fields |
| Those starting with On | The Python procedure that GeoData Manager calls when an event happens |
| Group1 | If blank, you can not make a site group of these data sets |
| GroupMany | If blank, you can not make a tag group of these data sets |
| Those starting with Site | Defines how a data set finds its location see here |